Utilizing RAG in your Production Applications



As we explore Retrieval Augmented Generation, it’s essential to recognize the foundational role of LLMs in this domain.
Why choose RAG?
In the context of RAG, LLMs serve as the foundation. Almost all Large Language models can be augmented with external information retrieval systems to enhance their ability to generate contextually relevant responses. By combining the power of LLMs with retrieval techniques, RAG systems achieve more accurate and contextualized results.
Retrieval-Augmented Generation enhances LLMs by integrating them with external knowledge sources. This integration allows RAG to dynamically retrieve information during the generation process, leading to outputs that are not only contextually rich but also factually accurate.
How RAG works
RAG usually consists of the following components:
- Retrieval Process: In RAG, the external data can come from multiple data sources, such as a document repository, databases, or APIs.
-
- The first step is to convert the documents and the user query in the format so they can be compared and relevancy search can be performed. To make the formats compatible for doing relevancy search, a document collection (knowledge library) and the user-submitted query are converted to numerical representation using embedding language models. The embeddings are essentially numerical representations of concept in text.
- Next, based on the embedding of the user query, its relevant text is identified in the document collection by a similarity search in the embedding space.
- Augmentation: Then the prompt provided by the user is appended with relevant text that was searched and it’s added to the context. The prompt is now sent to the LLM and because the context has relevant external data along with the original prompt, the model output is relevant and accurate. Once the relevant information is retrieved, RAG augments the LLM’s intrinsic knowledge with this external data. This is done by feeding the retrieved documents into the LLM, which then generates a response that incorporates both its pre-existing knowledge and the newly retrieved information.
- Iterative Refinement: RAG systems often employ iterative refinement techniques, where the initial output is used to perform further retrieval operations, refining the response until it meets a certain threshold of relevance and accuracy.
Why is it Better?
- Enhanced Accuracy: By leveraging external databases, RAG reduces the likelihood of generating factually incorrect content, a common issue known as “hallucinations” in LLMs.
- Up-to-date Information: When augmented externally with up-to-date information LLMs essentially become RAG systems which can access the latest information, making them very useful for knowledge-intensive tasks that require data that they weren’t trained on.
- Domain-Specific Knowledge: LLMs are trained on humongous datasets, datasets which are not essentially focused on one domain. Augmenting these systems with domain specific information tends to help these systems become more focused and a subject matter expert.
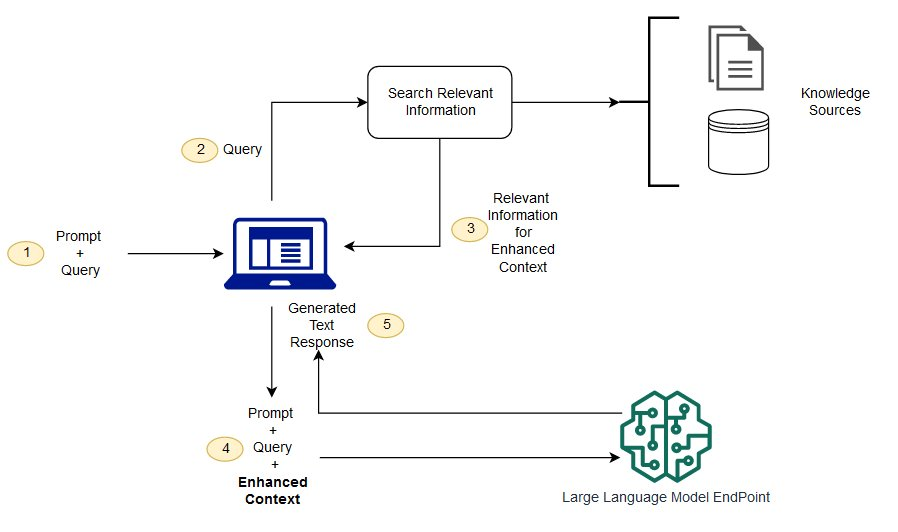
Implementing RAG in production:
As these models become increasingly prevalent in industries ranging from customer service to content creation, it’s crucial for businesses and developers to be mindful of the potential pitfalls and to implement robust strategies for monitoring, quality assurance, scalability, and security. The interplay between these considerations can be complex.
Best Practices with RAG in Production:
Deploying these systems in a production environment comes with a unique set of challenges.
Monitoring
To ensure a RAG model functions effectively after deployment, continuous monitoring is essential. Unlike traditional applications, the performance of a RAG model is not solely dependent on code stability but also on the interplay between the model and the ever-evolving nature of language and information. Monitoring should encompass:
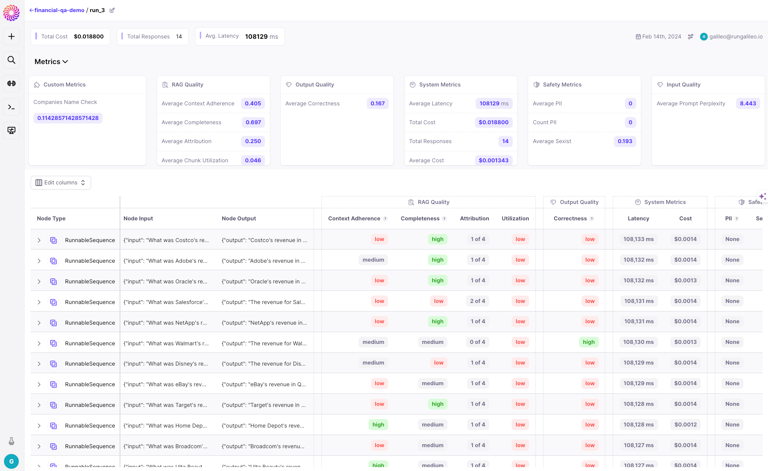
- Quality checks: Regular evaluation of the model’s output quality against a curated dataset is necessary to ensure the outputs remain accurate and relevant. Galileo provides in-depth interfaces to monitor your application’s quality of responses.

- Usage metrics: Tracking how often the model is used, for what purposes, and by whom can provide insights into its value and areas for improvement. For this, introducing an observability stack is important. While applications like Langfuse and Galileo provide adequate observability, localized support is also important in addition to support for local LLMs.
- Feedback loops: Implementing user feedback mechanisms can help identify when the model provides incorrect or suboptimal responses, allowing for iterative improvements.
- Human oversight: Perhaps the most critical among these is having a human in the loop to review and correct outputs can be a necessary safeguard. Additional metrics like confidence scoring and hallucination detection can be helpful in understanding and mitigating the risk of inaccurate answers.
RAG based applications range from simple chatbots to complex multi-agent systems that are able to interact with the real-world just like a human. The deployment of RAG models can significantly impact various business aspects, such as customer support, content creation, and knowledge management.
Important Considerations
As the usage of RAG models grows, the ability to scale becomes critical. To address the challenges that come with scale, being mindful of its impacts is important. Considerations in this regard include:
Infrastructure: Ensuring that the underlying infrastructure can handle increased loads without degradation in performance. Utilizing platforms like Kubernetes can help ensure scalability of locally running LLM applications. Here’s a great blog by OpenAI that details their story of scaling to 7500 nodes for their mission critical applications.
Data Security: When deploying RAG models, safeguarding sensitive data is paramount. Key data security measures include:
- Access control: Restricting access to the retrieval databases and the model’s outputs to authorized users.
- Encryption: Employing encryption for both data at rest and in transit to prevent unauthorized interception or alteration.
- Compliance: Adhering to data protection regulations such as GDPR or HIPAA, especially when dealing with personal or medical information. In conclusion, the production deployment of Retrieval-Augmented Generation models offers exciting opportunities but also demands careful attention to a variety of complex issues. By rigorously addressing monitoring, hallucinations, business impact, scaling, and data security, you can harness the power of RAG models while minimizing risks and maximizing benefits.
Pitfalls with RAG Applications in Production
While scaling up a RAG model to handle a larger user base can potentially improve business efficiency and user experience, it may also increase the risk of data breaches if security measures are not scaled up accordingly. Similarly, while adding human oversight to mitigate hallucinations can enhance the reliability of a RAG model, it may also introduce additional costs and limit scalability.
Furthermore, the dynamic nature of both language and the information landscape means that RAG models require continuous updates to their knowledge bases, which can pose challenges in maintaining accuracy without sacrificing performance. This also ties into the monitoring and feedback loops, as user engagement with the model can provide valuable data for these updates.
Ethical considerations are also an integral part of deploying RAG models, particularly when it comes to the potential spread of misinformation due to hallucinations. Organizations must balance the drive for efficiency and innovation against the imperative to provide trustworthy information, especially in sensitive areas such as healthcare or finance.
Lastly, as regulations around data privacy continue to evolve, compliance becomes an ongoing concern for businesses using RAG models. Ensuring that these models adhere to the latest standards is not just a matter of legal necessity but also of maintaining user trust. In order to stay informed about the latest developments and to effectively address the challenges associated with RAG models, organizations may benefit from engaging with experts in AI ethics, data security, and NLP. By doing so, they can create a framework that not only leverages the capabilities of RAG models but also aligns with broader societal values and expectations.
Conclusion
RAG represents a significant advancement in natural language processing, leveraging the foundation provided by LLMs to integrate external knowledge. By dynamically retrieving information during the generation process, RAG systems produce significantly accurate outputs.
However, deploying RAG models in production environments comes with its own set of challenges and considerations. Robust strategies for monitoring, quality assurance, scalability, and security are imperative to ensure the effectiveness, reliability, and ethical integrity of these systems.
Despite their challenges, RAG applications can help businesses reduce cost and improve productivity with minimal configuration. RAG systems have become increasingly resilient and provide an important foundation for most LLM models in production due to its reduced cost (compared to fine-tuning) and increased accuracy.
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.