Data Pipelines and Their Components: An Insight



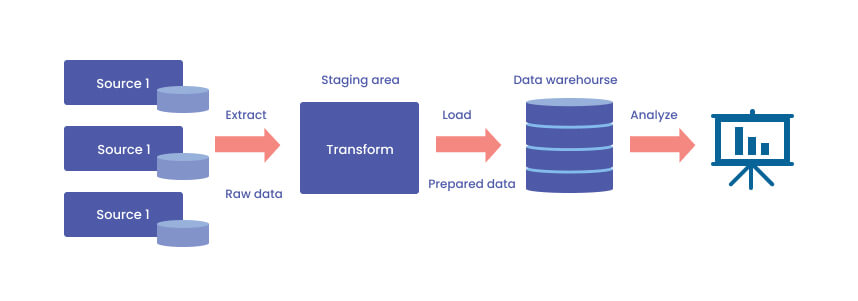
Data pipelines usually consist of multiple components depending on the complexity of the pipeline. It can be as simple as consisting of two or three key components: a source, a processing step or steps, and a destination, and as complex, and more commonly, as source(s) destination(s), processing, storage, monitoring, dataflow, workflow, etc.
Depending on the problem statement and its complexity, we need to incorporate certain data processes. Some of these are transformations, while others fall under integration and data management umbrellas.
These processes include data modeling, data quality, data governance, and data lineage and help in making the pipeline more optimized and efficient, and the performance of the pipeline is improved as well.
Data Processes of Data Pipelines
As mentioned before, pipelines are generally a combination of one or more different elements, usually connected in series. These, with the addition of a few more, are the main components of a pipeline, and they vary according to the type of data pipeline that is being developed.
While developing these pipelines on the cloud, the developer has numerous offerings that are available for each of the components of a pipeline from all the Cloud Platform Service Providers, such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform.

In this section, we will also dive deep into the different data processes and components of all data pipelines. As mentioned, these cover integration, transformation, and data management.
These processes include Data Quality, Data Governance, Data Modeling (if required by the problem statement), and Data Lineage. These aspects are critical in developing a data pipeline(s).
With the current offerings required to create data pipelines, a developer can use multiple offerings to help apply the above-mentioned essential aspects to a data pipeline. For example, Data Quality can be implemented in AWS using AWS Glue DataBrew, Amazon Athena, and Amazon QuickSight by building a data quality scorecard. Data Modeling can be done on Microsoft Azure using the data modeling tool SQLDBM, which can be used for both Synapse and SQL Server.
Data Quality
Data Quality is essential for all pipelines as it ensures that the source data is accurate, complete, consistent, and up to date to ensure that no issues are faced while using said source data for integration through data modeling, data visualization, reporting, etc.
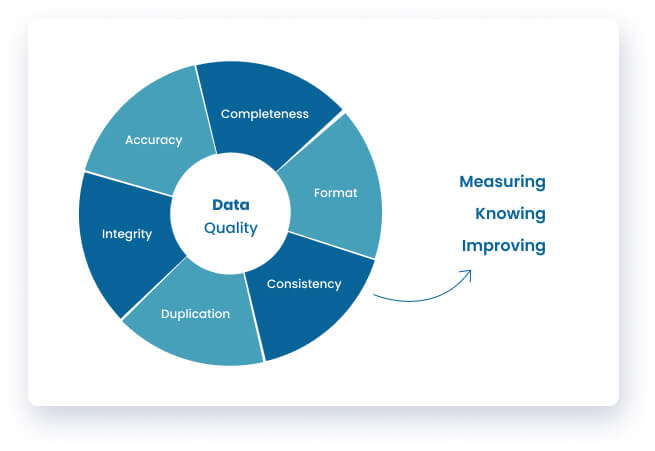
Data can be sourced and stored in multiple forms, but the five characteristics of data, more commonly known as the 5 C’s, apply to all formats of data, namely: clean, consistent, conformed, current, and comprehensive, which state the following:
- Clean: Clean data means there are no missing values (unless otherwise specified, such as NULL values) no inaccurate values which may include incorrect formats, typos, garbage values, and full-row duplicates, etc. Such inconsistencies in the data are usually cleaned via certain low-level transformations in a pre-processing phase known as staging.
- Consistent: Consistent data means that the data is the same across the organization; that is, there is a single version of truth, that is, the total sales in a given month are the same across the organization. Also, the data representation should be the same across the organization. For example, the citizen identification number should be 13 digits without hyphens across the organization rather than being stored with hyphens in some source systems. This data consistency can be achieved through Master Data Management.
- Conformed: Conformed data means that the data is within the established boundaries of the organization. That is, all the data sourced and stored is the necessary and relevant data as per the chosen metrics. Any data outside of the conformed boundaries that is not meeting the decided metrics should not be sourced and stored. For example, in a bank, data containing customer demographics that are relevant to the customer profile is conformed, such as address, date of birth, place of birth, etc. Information such as mobile handset used is not conformed.
- Current: When it comes to data, current can be respective to the type of analysis being performed. This can be streaming data analysis, which will be in real-time, or historical data analysis which can be multiple months or years, or regular batch analysis which can be near real-time or a day -1 data. Data is usually categorized as Hot or Cold depending on the analysis to be performed. Hot data refers to data that is accessed frequently, whereas cold data is not accessed as frequently.
- Comprehensive: Comprehensive data means that the relevant data required for analysis is complete; that is, for a customer-centric analysis with customer demographics, the data needs to be complete and detailed with information such as full name, title, address, mobile number, home number, primary and secondary email addresses, date of birth, place of birth, etc.
Data Governance
Data Governance is equally, if not more, essential while creating a data pipeline as it guarantees that the data is available, usable, secure, and has undergone the data quality checks according to the organization’s internal policies as per the 5Cs of data quality. Good data governance further ensures that all the data quality and data governance policies and rules are properly documented. Data Quality and Data governance go hand in hand. Data Quality is the set of rules regarding the integrity and value of the data, whereas data governance is the procedure of enforcing the rules for data integrity, value, security, and availability.

Data Modeling
Data modeling is the process of defining and ordering unordered data by creating relationships between different source tables and creating new tables from those relationships. It is used for analysis by certain business end users.
Data modeling results in high quality, consistent, structured data, which in turn helps in the execution to become optimized and which results in high performance and helps in achieving consistent results.
A Data Model helps integrate different source systems to provide a single source of the truth and is one of the building blocks of a data warehouse.
There are multiple types of data models, the top four types of data models used are the Hierarchical Data Model, the Network data model, the ER (Entity Relationship) data model, and the Relationship data model. Each of the data models has its advantages and disadvantages.
However, the most commonly used data model amongst the four is the ER data model, which is scalable and efficient and allows additions and removals of relationships and entities as per business requirements and product and application development.
There are also dimensional models that are used for reporting and visualizing the aggregated data. Dimensional models are built on Fact and Dimension tables. Fact tables are made up of the measurements and metrics which are essential facts of a particular business process. Dimension tables consist of attributes that describe the objects in fact tables.
Data Lineage
Data Lineage is the understanding and visualizing of the manipulation data goes through from source to Target in a data pipeline. The most commonly used method for moving data is Extract, Transform, Load (ETL), in which data lineage allows developers and users to assess the quality of their data before it is transformed and processed. Data catalogs are used to manage data lineage and data flow by creating an organized collection of the data assets and metadata which helps us understand the data flow and data lineage that is the lifecycle of the data from its origin to destination. This helps in Machine Learning Operations, Data Engineers and Quality Assurance Engineers in Unit testing and end-to-end testing of pipelines, respectively, as data lineage and data cataloging provide the advantage for them to ensure that the data is coming from a trusted source, has been transformed correctly according to the specified rules, and design parameters decided and loaded to the correct and specified target destination.

Some data catalogs that are widely used in data pipelines today are AWS Glue Data Catalog, Microsoft Purview, Microsoft Azure Data Explorer, and Google Data Catalog.
Components of Data Pipelines
While creating data pipelines for data migration, data engineers need to keep into account the following components, as depending on the complexity of the problem statement, a minimum of two of the following components will be part of the data pipeline. These components are essential for all pipelines, whereas some are essential for data pipelines only. These will be made part of the data pipeline if required in the problem statement.
Sources
The Source(s) where all original raw and unprocessed/untransformed data is present. The format in which data is present varies. It can be as simple as a simple file in .txt or .csv format or more complex semi-structured file formats such as JSON, Parquet, and AVRO. The source(s) could be a database with data stored in a structured or semi-structured format, for example, various RDBMS such as MySQL, PostgreSQL, IBM Db2, Teradata, Oracle, Microsoft SQL Server, and Apache Hive or NoSQL databases such as MongoDB, Apache Cassandra, HBase. These can also be cloud platform products such as Azure SQL Database, Azure SQL Database for Postgres and MySQL, Azure Cosmos DB, Amazon RDS, Amazon Aurora, and Amazon DynamoDB. Other sources may include data marts, operational data stores, streaming data, and real-time and near real-time data.
There are multiple sourcing mechanisms, and they will vary depending on the solution for which the pipeline(s) is being developed and the state in which the source data is being stored at the source. The data stored can be a slowly changing dimension(SCD) with one of the different types of SCD types applied, and we can source data accordingly. The data stored can also be a change data capture where the data already sourced and the latest data in the source are compared and only the new and updated/changed data is identified and loaded. In certain sources, only the data that is latest will be available to be loaded completely, and no particular mechanism will be used. In certain cases, the complete source data will be loaded in every batch. In such cases, a sourcing mechanism will have to be introduced to save time and performance.
Destinations
The Destination(s) is the final endpoint to which the data is transferred. The final destination(s) can vary according to various problem statements and solutions. The destination(s) can range from a simple Operational Data Store in a database such as MySQL, PostgreSQL, IBM Db2, Teradata, Oracle, Microsoft SQL Server, and Apache Hive, a Data Warehouse such as Amazon Redshift, Microsoft Azure Synapse Analytics, Google Big Query, Oracle cloud-native data warehouse, a Data Lake such as Apache Hive, Microsoft Azure Data lake analytics, MapReduce, an analytics tool such as Microsoft PowerBI, Microsoft Azure Data Lake Analytics, Microsoft Azure Synapse Analytics, HDInsights, Amazon Quick Sight, Amazon Kinesis, Microsoft Azure Stream Analytics, etc.
Like sources, there are multiple mechanisms to load data into destinations. These primarily include the mechanism used in loading the final destination table. The destination loading mechanism varies according to the different solutions and problem statements. For a destination that is a slowly changing dimension(SCD), one of the different types of SCD types is applied. The destination loading mechanism can be a simple insert, Full data merge (Upsert), a Delta merge, or a truncate insert.
Dataflow
Dataflow refers to the movement of data between the origin and destination. All pipelines are data flows. Some dataflows do not require any major transformations and are only created for data movement as well such as from one database to another database or file storage and vice versa. One example of this is that a pipeline can be developed to move the source data from the source to a staging area continuously as soon as new or updated data is made available and the staging area for another pipeline. Depending on the problem statement and the requirements of the pipeline, data flow goes through different processes, such as Ingestion
Transformation and components, such as storage and monitoring, are usually the different offerings of the many cloud service providers.
Storage
In any data pipeline, all the data is usually stored at every stage and process. Starting from the sources, then the ingestion phase, the data is ingested from the source to a particular staging area or intermediate storage component. This can be a database, a storage platform, a compute engine, etc. For any cloud service provider, it can be AWS S3, Microsoft Azure Blob Storage, Google Cloud Storage, Amazon RDS, Amazon Redshift, Microsoft Azure SQL Database, Microsoft Azure Synapse, Google Cloud SQL, Google BigQuery, etc.
Processing
All the processes in a data pipeline depend on the problem statement and the complexity of the data pipeline. It could be as simple as just ingestion from a source to a target or it could be as complex as ingestion of various sources and multiple transformations where the sources are of different formats, including sources that require parsing and real-time streaming data.
The multiple transformations are performed at all the different databases or compute engines.
Monitoring
Monitoring a data pipeline includes various metrics such as the start time, end time, time elapsed, logs, error information in case of failure, rows at each process of the pipeline, and the status of the pipeline at each phase of the data pipeline. Some of the many monitoring offerings of the different cloud service providers or on-premises tools are AWS Data Pipeline, AWS Glue, Microsoft Azure Data Factory, Google Data Fusion, Google Cloud Composer, Informatica Monitor, and IBM Datastage Operations Console.
Conclusion
Data pipelines are the backbone of any data warehouse and analytics department. The combination of multiple data pipelines creates the workflows to load data from sources to reporting and visualization or AI/ML tools. The components and processes of data pipelines are evolving. Now, there are tools and offerings that can do multiple processes, such as Microsoft Azure Synapse Analytics, which can now process all the transformations and analytics.
With these technological advancements, developing a data pipeline to address a particular problem statement will become easier as the developer will have multiple offerings and components to choose from to develop said data pipeline.
The advancements will further result in better performance and optimized data pipelines and will take much less effort.
Related Articles



Related Articles
Established in 2012, Xgrid has a history of delivering a wide range of intelligent and secure cloud infrastructure, user interface and user experience solutions. Our strength lies in our team and its ability to deliver end-to-end solutions using cutting edge technologies.
NAVIGATE
Cloud & DevOps Web & Mobile Apps Temporal Digital Marketing GTM Engineering Marketo Consulting HubSpot Consulting Company Careers ResourcesOFFICE ADDRESS
US Address:
Plug and Play Tech Center, 440 N Wolfe Rd, Sunnyvale, CA 94085
Dubai Address:
Dubai Silicon Oasis, DDP, Building A1, Dubai, United Arab Emirates
Pakistan Address:
Xgrid Solutions (Private) Limited, Bldg 96, GCC-11, Civic Center, Gulberg Greens, Islamabad
Xgrid Solutions (Pvt) Ltd, Daftarkhwan (One), Building #254/1, Sector G, Phase 5, DHA, Lahore
Xgrid © 2026. All rights reserved.